PROLOGUE
Today I would like to tell you not about a model project, but about a project around modeling) I don’t know how acceptable this is, but this is not a commercial project, it is made on pure enthusiasm, which looks useful for the modeling community and it is original. I read the rules, but I did not understand for sure whether to consider this story spam or not. I hope not, so I will try.
This year I had a creative ecstasy and made a hobby project for modelers ![]() . I will point out right away - this is not a group or a channel for reposting other people’s works from around the world and not an author’s blog. This is a full-fledged functional resource inside Telegram. How successful it turned out - you, those who are “sick” with this hobby together with me, will decide. Please do not judge my adventure too harshly. Now I will tell you everything…
. I will point out right away - this is not a group or a channel for reposting other people’s works from around the world and not an author’s blog. This is a full-fledged functional resource inside Telegram. How successful it turned out - you, those who are “sick” with this hobby together with me, will decide. Please do not judge my adventure too harshly. Now I will tell you everything…
IS IT POSSIBLE FOR THE RATING TO MEAN SOMETHING?

I have been in modeling for quite a long time and even longer online. And I have always lacked some kind of catalog of works with an adequate, fair assessment. So that the comparison would not be “in a vacuum”, but in context. Like in sports: go to the table and see who the champions are, who are solid middle-of-the-roaders, and who still needs to practice. Or evaluate yourself, in which league my work? How could we do without it: if not a master, then at least not so bad, nice, there is room to grow. Sound familiar?
I have not found anything like this on the web. I am not saying that there are no rating systems. There are, with different approaches, but each has too many shortcomings. There is no simple, transparent and unified system. And there are often no rating lists themselves. I am not blaming anyone, it was just not a priority for existing resources. They did not consider it important. Well, I am itching.
Assessing creativity of any kind is always a pain, always a scandal. Who is cooler - Caravaggio or Raphael? Metallica or Iron Maiden? De Niro or Nicholson? I am aware of the problem, understanding in advance that it will not be possible to measure seconds, meters, rivets and other objective quantitative characteristics. And yet, you can try to level out the factor of subjectivity and other shortcomings as much as possible.
Free evaluation? It is devalued. In most cases, people give the highest possible ratings, and a masterpiece and an average work will stand on the same pedestal. And why? Because people do not know about this masterpiece, they vote for a specific model here and now. And it is not bad. There is nothing to compare with, no support. And there is no time to figure it out and think about the evaluation. We are not at an authoritative tournament, there are no judges, regulated criteria, or experience.
Or maybe this is a friend’s model, huh? How can you offend? Or vice versa: the author is unpleasant, he disputed on the forum that the earth is flat, I’ll teach him a lesson. I’ll give him 1 out of 10.
Views, likes? Too much influence of hype or cheating. Popularity and quality are often different things.
And what about the influence of authority? “I’m a simple man, I see the work of a grandmaster of scalpel and airbrush - I give it 10 out of 10.”
Manipulation? Registering fake accounts on a website/social network isn’t hard, right?
You say offline/online tournaments with judges are an option? An option, but! How to organize a continuous process of evaluation by an authoritative panel of judges? This tournament should be permanent. This is a utopia and we can end here. But if we reveal it, then: a long process, a set periodicity, many personal organizations of the modeler for participation in offline tournaments. Ok, the first three places and the “wooden medal”, but what about the rest? How are they distributed relative to each other? Again, the panel of judges is narrow, which means the influence of subjectivity increases. Is scaling even possible in such conditions? And where can I see the results, conveniently, for all years, all categories? And the human factor: twinning, prejudice, conflict of interests … No, tournaments are a cool, but closed story. A cross-section of “here and now” in a certain territory for laureates, medalists. The rest equally “couldn’t do it”.
I just want the rating to mean something. Literally. Will it work? Let’s see…
THEORY

![]() Let’s stop screaming in despair, I have an idea! I’ll start with the foundation, I propose a solution based on two pillars.
Let’s stop screaming in despair, I have an idea! I’ll start with the foundation, I propose a solution based on two pillars.
The first is a paired comparison. I called it “duels”. What if we create a system where models are compared in pairs? It works like in dating apps: there are models there and there are models here, but there is a nuance😉. It is always easier to choose the best of two than to think about points. And the bot will calculate everything itself. Of course, everyone has their own criteria, some like skinny, others like plus size, and in general it depends on the period of life😏. But the scale effect works. One way or another, great work will still come out on top with a large number of “duels” in a fair confrontation with a variety of opponents and taking into account that different people vote. And vice versa. Pairs are selected based on many criteria, everything is aimed at finding a worthy and adequate opponent for everyone, and not just a random one from the database, which excludes empty battles between an elephant and a muzzle. A plus in the process of duels is the anonymity of the authors, which partly reduces the influence of authority / hate.
The second whale comes into play after the first one — the Elo rating algorithm . Yes, the same one used in chess. And instead of varnished black and white armies, we have a plastic Messerschmitt and Il-2. Spoiler: of course, not only them and not only plastic😎. There will no longer be this fight for hundredths in the 9.5-10 range, as in a free assessment, which means nothing. If someone gains rating, then someone loses, but in different proportions. Everything is fair. It is impossible to beat everyone, and if possible, then the work is worthy of being at the top of the rating. In my adaptation of the rating, works are distributed across the entire range of ratings 0-100. But being above average is already very honorable, so with a rating of 55 you will get bronze🥉, with 65 - silver🥈 and so on, up to the crown👑 from 90. In practice, a difference in rating of 20 points means that the probability of victory of the stronger one is an order of magnitude (10 times) higher. There are many details, coefficients that I do not want to bore you with. In short: new products gain rating faster, they have priority; on the contrary, it is difficult to shake the rating of “veterans”; the calibration period cuts off the extremes of the first ratings, the work gets into the rating after 25 duels, etc.
Of course, you can’t vote for yourself, and for each specific pair of works - only once. Telegram with its difficult registration of fake accounts is a good shield against cheating.
Of course, I don’t deny that there are some shortcomings here. The rating should be perceived as “vox populi”, how most of your colleagues see your work. It is impossible to achieve the ideal, but it looks like the rating really means something now.
PRACTICE

I ran several test simulations, tweaked them, and realized that the “duels” looked viable. The model was ready, where to implement all this and on what? Well, I had an answer to the last one - on personal enthusiasm and caffeine. But where? A website? A huge amount of work and reinventing the wheel, an unbearable price for a pilot project. An application? A little less, but the same problems. And you also need to install it, register. And then I looked at Telegram and realized - here it is, a universal soldier. Almost everyone has it, it works quickly, stably, many functions (notifications, posting, sharing, comments, etc.) have already been implemented. Well, and an API for bots that allow you to implement other fantasies.
A great theory and smooth on paper. In practice, there are endless ravines. Telegram bots don’t like to be smart. They have many limitations, crutches and strange features. It would be more correct to say - unexpected. The bot was born with difficulty, like an assembly of old Airfix products. At some point, it became like a pet for me: sometimes it doesn’t eat, sometimes it doesn’t listen, sometimes it suddenly falls asleep on an important command. But, I trained it💪🏻.
WHAT’S NEXT?
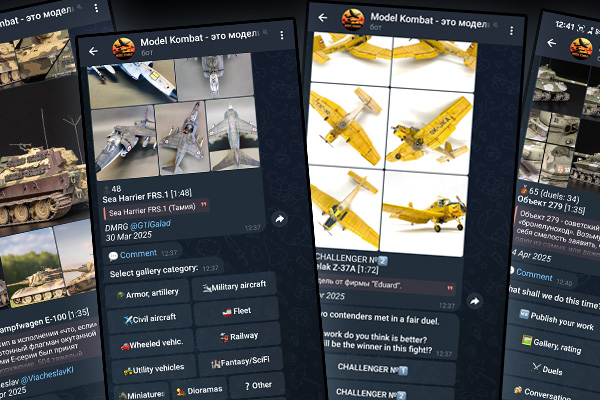
![]() The bot turned out. A bit twitchy, like me at 3am, but alive. Calculates the rating. Displays the gallery. Listens to commands. The first users have arrived, they are uploading works, voting, thousands of duels have already taken place, they are watching the rating. I thank them and appreciate them.
The bot turned out. A bit twitchy, like me at 3am, but alive. Calculates the rating. Displays the gallery. Listens to commands. The first users have arrived, they are uploading works, voting, thousands of duels have already taken place, they are watching the rating. I thank them and appreciate them.
And there are also filters: by category, by scale, by era and soon by country. And comments on each model. And a personal gallery. And a forum. There’s more to come.
I wanted to create a cozy, modern space for modelers. Which is always at hand. Not littered with advertising. With a practical function - a rating that matters. Of course, free for you, too bad not for me😊.
Worked, did it. Not perfect, but diligently. I will continue, I have many plans. A lot of work has just been completed on localizing the bot into English and Spanish.
Interesting? Close? Publish, play “duels”. Thanks for your interest, in advance.
![]() Here is it — Model Kombat in Telegram (or @ModelKombatBot in Telegram search)
Here is it — Model Kombat in Telegram (or @ModelKombatBot in Telegram search)